e18480e185b3e186b7e1848be185b2e186bce18483e185a6e1848be185b5e18490e185a52e1848ce185a9_e18492e185aae186bce18480e185b3e186b7e18483e185a6e1848ce185b5-1다운로드하기
Month / 2020 9월





























Big data analysis system
| App |
| hive, Pig, R : 데이터 프로그래밍 언어 pig(야후) : 데이터 처리 hive(페이스북) : 데이터 웨어하우스 r(오픈소스) : 데이터분석 |
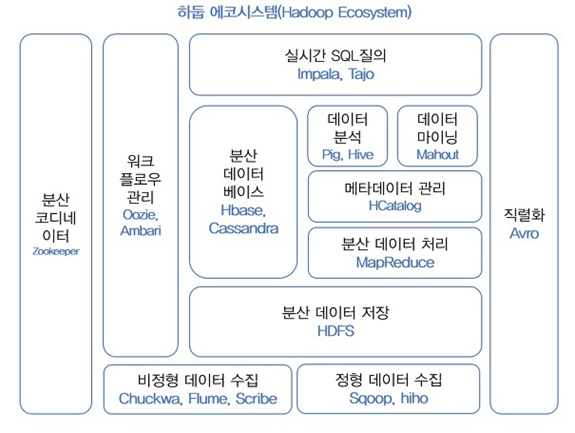
| Hadoop : 데이터 접근 권한/데이터베이스) 대용량 데이터를 분산 처리할 수 있는 자바(Java) 기반의 오픈소스 프레임워크. 비영리 조직인 아파치(Apache)에서 구글의 빅데이터 분석 프레임워크를 따라 하둡을 만들어 오픈소스로 공개 [문제점] 하드디스크 드라이브 저장용량은 크게 정가한 반면 액세스 속도는 그에 못미침 (예 : 1테라를 읽으려면 2시간 반 소요) [해결방안] 여러 디스크로 데이터를 나누어 한번에 읽어들이기 [실현 방법] 데이터베이스 / 맵리듀스(key-value) 이용 (분산 데이터 처리 시스템) HBase : 분산 데이터 저장소 클라우드 데이터와 유사 |
| HDFS(Hadoop Distributed File System) : 분산 파일 시스템 – 대용량 파일을 특정 크기의 블록으로 나누어 분산된 서버에 저장하여 데이터를 빠르게 처리할 수 있도록 하는 파일 시스템. 기존의 파일 시스템(NAS/DAS/SAN)에 비해 저사양의 서버로 스토리지를 구성할 수 있음 Swift |
| Scale-out Cluster : 저장소 |
Challenges in Data Science
<과거의 해결과제>
- VLDB : Very Large DataBase. 아주 큰 데이터 베이스. 아주 큰 데이터셋을 어떻게 다룰것인가?
2. Parallel Processing : 병렬처리로 처리 속도를 향상시켜보자
<해결>
IPA “Scalable and Parallelizable Processing of Influence Maximization (2013)
<현재의 해결과제>
- Big data system is complex and slow
- Big data is rare / Active data is small
Database
데이터베이스
- (논리적으로 연관된) 데이터들을 구조화/체계화한 것
[특징]
- 효율적인 검색과 갱신
- 데이터 중복 최소화
- 데이터 무결성(정확한 정보)
- 데이터 일관성
- 데이터 독립성
- 데이터 표준화
- 데이터 보안
RDBMS
- Relational DataBase Management System
- 관계형 데이터베이스 관리 시스템
- 관계를 표현하기 위해 2차원 표 사용.
[development]
- relational database management
- data warehousing
- data mining
- big data
SQL
- Structured Query Language
- RDBMS를 관리하기 위해 설게된 특수 목적의 프로그래밍 언어
[종류]
- DDL, DML, DCL (Definition/Management/Control)
